
Commençons par un peu d'histoire...
La notion voit le jour en 1950 dans le livre Computing Machinery and Intelligence écrit par le mathématicien Alan Turing qui suggère d’apporter aux machines une forme d’intelligence. Il propose même un test (Turing test encore utilisé aujourd’hui): le sujet humain interagit alternativement avec une machine et un humain. Si l’humain n’est pas capable de faire la différence entre les deux, alors la machine peut être considérée comme intelligente.
En 1955, John McCarthy et ses collaborateurs organisent une conférence intitulée Darmouth Summer Research Project on Artificial Intelligence qui a donné naissance aux bases de l’intelligence artificielle soit : le machine learning, le deep learning, les analyses prédictives et prescriptives. Ce n’est qu’en 2010, avec l’essor des données (lié au développement d’internet) que la science des données apparait et permet de véritablement mettre en pratique l’ensemble de ces outils.
"Les tentatives de création de machines pensantes nous seront d’une grande aide pour découvrir comment nous pensons nous-même" (Alan Turing)

#1 LE PRINCIPE
En santé comme dans tous les domaines actuellement, les process deviennent de plus en plus complexes générant toujours plus de données à traiter. L’intelligence artificielle est un outil permettant de traiter ces données plus rapidement et plus efficacement pour aider à résoudre des processus décisionnels complexes.
Prenons un exemple:
Une partie de morpion: c’est 255 168 parties possibles dont 46 080 mènent au match nul. On considère qu’il est facile pour un être humain d’apprendre à ne pas perdre au morpion.
Mais si on complexifie:
- Une partie d’échec: c’est 10120 parties uniques jouables.
- Une partie de dame: c’est 500 x 1018 parties uniques jouables.
La quantité de données à prendre en compte devient colossale pour un cerveau humain. Dès 1930 née l’idée d’intégrer ces données dans une machine pour qu’elle puisse vaincre un joueur d’échec humain. L’essai est transformé en 1997, lorsque l’IA Deep Blue d’IBM défait le champion du monde en titre Kasparov. Depuis des championnats du monde d’échec entre IA ont vu le jour dont le plus connu le World Computer Chess Championship.

#2 CONCRÈTEMENT
L’intelligence artificielle est en fait une discipline qui réunit des sciences, des théories mais aussi de nombreuses techniques dont le but est de faire imiter par une machine les capacités cognitives d’un être humain.
Plusieurs types d’intelligence artificielle existent, mais deux sont particulièrement connues: le machine learning et le deep learning.
Machine learning
Le machine learning a connu son essor avec l’accroissement des données. Les big data, trop complexes à gérer et analyser pour un être humain, sont alors traitées par un algorithme. En 1959, le pionnier en la matière, Arthur Samuel le décrit comme « le champ d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmés pour ». L’idée est de nourrir un algorithme de données et de lui donner des éléments pour les analyser afin qu’il réalise une prédiction.
La machine va être nourrie par des données et des règles vont être édictées pour qu’elle traite les données correctement. Il est aussi possible de fournir à l’ordinateur les données ainsi que les résultats pour qu’il déduise des règles. Cela se traduit par 4 éléments à fournir: des entrées, des poids/coefficients, un seuil décisionnel et une sortie.
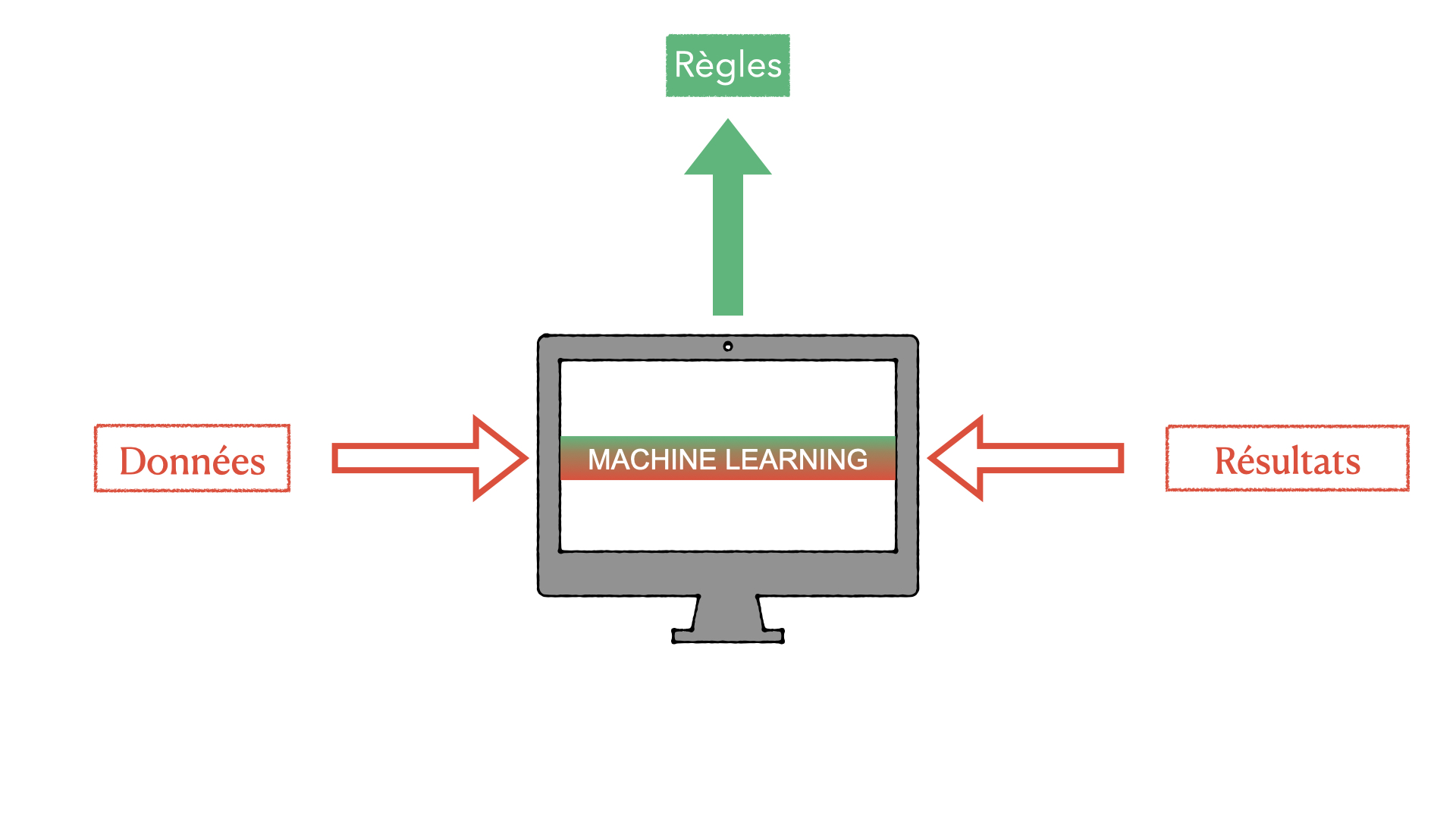
"Le champ d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmés pour" (Arthur Samuel)
Un exemple: nous voulons prédire si un patient va avoir une complication cardiovasculaire en peropératoire.
4 facteurs vont influencer ma décision et les données le concernant permettent d'obtenir les réponses:
- Ce patient est-il à risque cardiovasculaire ? Son interrogatoire m’apprend qu’il a un antécédent récent d’infarctus. Il est donc à risque : en binaire = 1.
- Est-ce que mon patient est sédentaire ? Son interrogatoire m’apprend qu’il n’a plus d’activité sportive depuis 10 ans. En binaire, on traduit par 1.
- Est-ce que mon patient présente des symptômes évocateurs ? L’interrogatoire et l’examen clinique ne retrouvent rien d’évocateur. En binaire, on traduit par 0.
- Est-ce que la chirurgie est à risque ? On va réaliser un Bricker donc une chirurgie majeure. En binaire, on traduit par 1.
=> Ici nous prenons des réponses binaires (0 = non, 1 = oui) pour l’exemple, mais les systèmes actuelles permettent de mieux nuancer les réponses.
Bien que ces éléments sont tous des facteurs de risque de survenu d’une complication cardiovasculaire en peropératoire, tous n’ont pas le même poids. Nous décidons alors de leur appliquer un coefficient différent:
- C1 = 5, l’infarctus récent est un risque important ;
- C2 = 3, la sédentarité est un risque à prendre en compte mais d’une importance relative ici ;
- C3 = 10, des symptômes évocateurs seraient un élément majeur ;
- C4 = 3, le type d’intervention fait varier le risque de complications post-opératoires ;
Enfin, un seuil de déclenchement est choisi (on pourrait dire 10 ici). En multipliant les données binaires avec leurs coefficients respectifs, on trouve 11. La fonction est donc activée car supérieur au seuil de 10.
=> Résultat: le patient est à risque de complication cardiovasculaire peropératoire;
Cette vision très simplifiée permet de comprendre le fonctionnement typique d’un algorithme de machine learning. Il n’y a rien de fondamentalement intelligent, cependant, à l’échelle de centaine ou de millier de patients, cet outils nous permet de gagner un temps considérable. De plus, en pratique, ils sont bien plus complexes et fonctionnent en réseau. Leur inspiration vient du cerveau humain et des réseaux neuronaux. On parle alors de réseaux neuronaux artificiels. Par exemple, un neurone arrivant au seuil de déclenchement, va déclencher l’algorithme d’un second et ainsi de suite… amenant à la résolution de problèmes complexes !
Dans notre exemple, on pourrait imaginer qu’un nouveau neurone soit activé avec un algorithme pour savoir si le patient devrait voir un cardiologue en pré-opératoire.
Le Deep learning
Le Deep learning a connu son essor plus récemment en 2012 avec l’augmentation de la puissance de calcul. En effet, le deep learning nécessite l’ingestion et le traitement de millions de données. La rapidité et la puissance de calcul deviennent donc l’élément limitant ici.
Le deep learning est un sous-ensemble du machine learning et est en fait un réseau neuronal composé de plus de trois couches de neurones. Un neurone est capable de réalisé une prédiction approximative qui peut être grandement affinée grâce à la création de couches neuronales supplémentaires.
L’avantage du deep learning c’est qu’il ne nécessite pas de données structurées permettant une économie de temps non négligeable. Il peut ingérer du texte ou des images et automatiser l’extraction de caractéristiques. Par exemple, on introduit des photos d’animaux que l’on veut classer par espèce. L’algorithme d’apprentissage profond peut déterminer quelles sont les caractéristiques les plus pertinentes pour les différencier (oreille, museau, queue…). Alors que le machine learning nécessite qu’un humain explicite cette règle manuellement. L’apprentissage et l’amélioration de l’algorithme se fait par un feed-back des neurones permettant d’améliorer la précision de l’algorithme.
.jpeg)
Comment apprennent-elles ?
Plusieurs façons d’apprendre: l’apprentissage supervisé et non supervisé sont les plus connus.
Apprentissage supervisé
Nécessite l’introduction de données étiquetées pour faire des prédictions. C’est à dire qu’on donne à la machine le problème et son résultat. L’objectif étant à terme que la machine puisse donner le résultat seule pour des nouveaux cas.
Exemple: Le radiologue introduit des mammographies avec leur classement ACR. À force d’intégrer des exemples, l’algorithme va pouvoir donner l’ACR pour de nouvelles mammographies.
Apprentissage non supervisé
On introduit des données non étiquetées (donc sans résultat). L’algorithme va devoir trouver des liens entre les données pour les ranger.
Exemple: trouver des liens/classer des données: on introduit des patients avec leurs habitudes alimentaires, leurs caractéristiques physiques, leur antécédents… dans l’espoir de trouver des facteurs de risque de pathologie cardiovasculaire.
#3 COMMENT S’APPLIQUENT-ELLES EN MÉDECINE ?
On a vu que l’intelligence artificielle fonctionnent de plusieurs manières. Son utilité actuelle en médecine se répartie en deux grandes catégories:
- Reproduire une activité humaine: diagnostic de mélanome sur photographie, reconnaissance d’une tumeur sur une imagerie, aide au diagnostic ECG mais aussi toutes les aides à la décision clinique…
- Servir la recherche: l’exploitation de bases de données cliniques géantes pourraient permettre la détection de nouveaux facteurs de risques pour certaines pathologies.
L’IA devrait nous permettre de diagnostiquer, de proposer un traitement personnalisé, de faciliter les prises en charge et très probablement de réduire les erreurs…
Il est donc fort probable que l’IA viennent bousculer de nombreuses spécialités en modifiant nos pratiques.
Mais va-t-elle vraiment remplacer le médecin ?
En 2018, une IA a réussi à détecter des tumeurs avec la même efficacité que le radiologue. Une application permet de détecter les mélanomes avec la précision d’un dermatologue. Une autre permet de prédire une hypotension artérielle au bloc opératoire 15 min avant sa survenue permettant à l’anesthésiste d’adapter sa prise en charge pour l’éviter…
Ces succès conduisent certaines personnes comme le pionnier du deep learning, Geoffrey Hinston à proclamer: « We should stop training radiologists now. It’s completely obvious that within five years, deep learning is going to do better than radiologists » (bon il l’a dit en 2016 donc à priori c’était pas si obvious que ça non plus).
"We should stop training radiologists now ! It’s completely obvious that within five years, deep learning is going to do better than radiologists" Geoffrey Hinston
#4 DOCTEUR VS MACHINE
Ces succès prédisent-ils nécessairement notre fin ? Impossible de prédire l’avenir mais en utilisant le modèle de l’aéronautique qui connait le pilote automatique depuis 1912, on peut proposer quelques éléments de réponses.
La responsabilité
Les avions commerciaux peuvent réaliser depuis quelques années le roulage, décollage, vol et atterrissage en parfaite autonomie. Et pourtant, pas un seul avion commercial sans pilote dans le ciel… En effet, de la même façon que pour les voitures autonomes, se pose la question de la responsabilité.
En cas de crash ou d’accident de la circulation, qui est responsable en l’absence de conducteur ou de pilote ? Cette question tourmente les juristes depuis déjà plusieurs années. Un objet ne pouvant avoir de responsabilité propre, reste seulement le constructeur. Mais les constructeurs sont ils prêts à prendre la responsabilité d’un crash d’avion ou de l’ensemble des accidents de la circulation ? Les développeurs sont-ils prêts à indemniser les patients opérés à tord pour une tumeur bénigne ou au contraire décédés car non diagnostiqués ?
A l’heure actuelle, la responsabilité reste largement portée sur le conducteur. En effet, il n’est pas responsable si et seulement si le pilote automatique a été activé dans les conditions recommandées et que le conducteur est prêt à reprendre la main à tout moment…
Le transfert de responsabilité totale ne semble donc pas être pour demain. Pourquoi ?
Les données peuvent expliquer en partie le problème.

Les données
Premièrement, les données engrangées par la machine seront à disposition du constructeur. A l’heure actuelle, elles sont bien évidemment protégées. En cas de litige, il faut qu’elles soient accessibles au minimum à la justice et aux experts à la façon d’une boîte noire pour qu’ils puissent analyser le contexte de l’accident. Il faut donc trouver un moyen pour que les données soient accessibles sans passer par une procédure complexe.
Deuxièmement, les ordinateurs dotés d’une intelligence artificielle se basent comme vous l’avez compris sur des données… Mais comment se comporteront-ils en l’absence de données ?
Trois exemples:
- Si des intelligences artificielles avaient du prendre en charge des patients COVID en 2020… qu’auraient-elles fait ? Auraient-elles compris comme les humains que l’intubation devait être retardée par rapport au SDRA habituel ? Auraient-elles élargi l'utilisation du decubitus ventral aux patients en ventilation spontanée ? Auraient-elles compris la ventilation de ces SDRA à compliance quasi normale ?
- En l’absence de pilote sur l’Airbus A320 US airways 1549. Aurait-il pris la décision d’amerrir sur l’Hudson ? Aurait-il, en l’absence de données tenté quoique ce soit ? N’aurait-il pas été plutôt programmé pour une stratégie de réduction du risque en allant s’écraser dans une zone désertique ?
- Le nouveau système MCAS des Boeings 737 Max entièrement automatisé aurait causé la mort d'au moins 346 personnes (l'enquête étant toujours en cours, le conditionnel est de mise). La sonde alimentant le système automatisé étant très fragile, elle gèle facilement. En l'absence de donnée, l'ordinateur de bord redresse inlassablement l'avion jusqu'au décrochage et au crash...
.jpeg)
Les exemples sont légions dans le domaine… L’absence de données est le point faible de la machine qui est bien sûr intelligente par sa capacité et sa vitesse de traitement mais n’en reste pas moins un ordinateur qui ne peut s’adapter aux situations totalement inconnues.
La réduction des erreurs
La réduction des erreurs est un argument fort en faveur des ordinateurs. En effet, toujours en aéronautique, quasiment 50% des accidents sont d’origine humaine.
En médecine, il est difficile d’estimer la part réelle des accidents liés aux facteurs humains. Le fameux articles du BMJ « l’erreur médicale troisième causes de décès aux USA » a été largement démonté point par point. Cependant, il est évident que nous faisons des erreurs. Une nouvelle étude du BMJ publié en 2019, estime cette fois à environ 6% les erreurs évitables et à 0,72% les erreurs évitables graves ou conduisant au décès.
Il est certain qu’une IA est plus fiable et diminuerait les erreurs. Cela a été prouvé et se comprend car elle ne présenterait ni fatigue ni stress.
Alors oui, l’IA permettrait très probablement une réduction des erreurs liées à des facteurs humains et elle bénéficierait sans aucun doute au patient.
En parlant des patients… qu’en pensent-ils ?
"Resistance to medical intelligence" est un article scientifique paru en 2019 dans le Journal of consumer research . Il nous apprend que les patients sont à l’heure actuelle peu enclins à l’idée de se faire soigner par des intelligences artificielles. En effet, quand le choix leur est laissé de se faire soigner par une intelligence artificielle ou un humain, les patients sont prêts à payer plus cher pour se faire soigner par un humain et même à prendre le risque d’avoir plus de complications !
Une explication résiderait dans le fait que chaque patient se considère comme unique et ne pense pas pouvoir « rentrer dans les cases » de l’intelligence artificielle. Il est possible que cette perception évolue avec les années et les générations mais quoiqu’il en soit, la machine ne pouvant être douée d’empathie, il parait difficilement concevable que ce choix change à court terme.
#5 ALORS QUEL AVENIR ?
On l’a vu, l’intelligence artificielle apporte une capacité d’analyse et de traitement excessivement pertinente en médecine. Elle nous permettra d’améliorer nos capacités diagnostiques, notre précision ainsi que la sécurité des patients. Elle sera très probablement un outil confortable qui permettra la réduction de la démographie médicale à demande constante puisqu’une partie des tâches quotidiennes du médecin sera automatisée et uniquement soumise à relecture.
Dans les prochaines années, les médecins seront sans doute assistés par l’intelligence artificielle permettant une amélioration de l’accès aux soins pour les patients en libérant du temps médical. Cependant, pour plusieurs raisons il est impensable qu’à court terme les médecins soient totalement remplacés par des bots… à moyen et long terme en revanche, l’amélioration des outils pourrait encore un peu plus diminuer la démographie médicale!
La technologie ne nous attendra pas, à nous d’évoluer avec.